Research topics
DB systems and DB applications
The topics about DB systems and DB applications we have recently worked on include lifelog management, query processing in wireless sensor networks, data stream processing, heterogeneous DB integration, business process management, Semantic Web, spatial data management, large knowledgebase processing, XML data management, and data warehousing/OLAP. A few R&D issues we currently focus on are described in more detail below.
- Lifelog Management
- Graph Data Management and Mining
- Query Processing in Wireless Sensor Networks
- Ubiquitous Business Process Management
- Data Stream Processing
- Semantic Web Data Processing
Lifelog Management
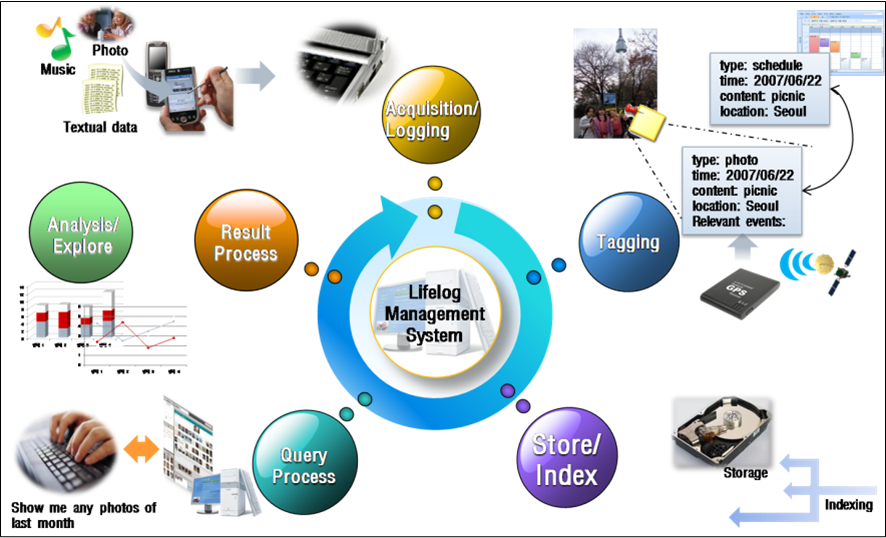
Lifelogs are what people see, listen to, and read in everyday life. Any type of data a user creates and consumes, such as a photo, video, music, a document, can be a lifelog. Even a user’s heart beat record or environmental information around the user at a specific time can be a kind of lifelogs. With the widespread use of the Internet and smart phones, gathering and sharing lifelog of a person became more popular. Moreover, a cheap cost of storages makes it possible to store lifelogs for the entire lifetime of a person. This has lead to the growth of research on lifelog management.
Research on lifelog management requires broad range of techniques; collecting lifelogs from various sources, tagging valuable information to lifelogs for precise query processing, indexing for fast lookup, ontology-driven semantic query processing. To support large-scale public lifelog management services, various techniques such as backup and recovery, large-scale storage management, load-balancing techniques, concurrent multiple query processing also should be deeply studied.
Graph Data Management and Mining
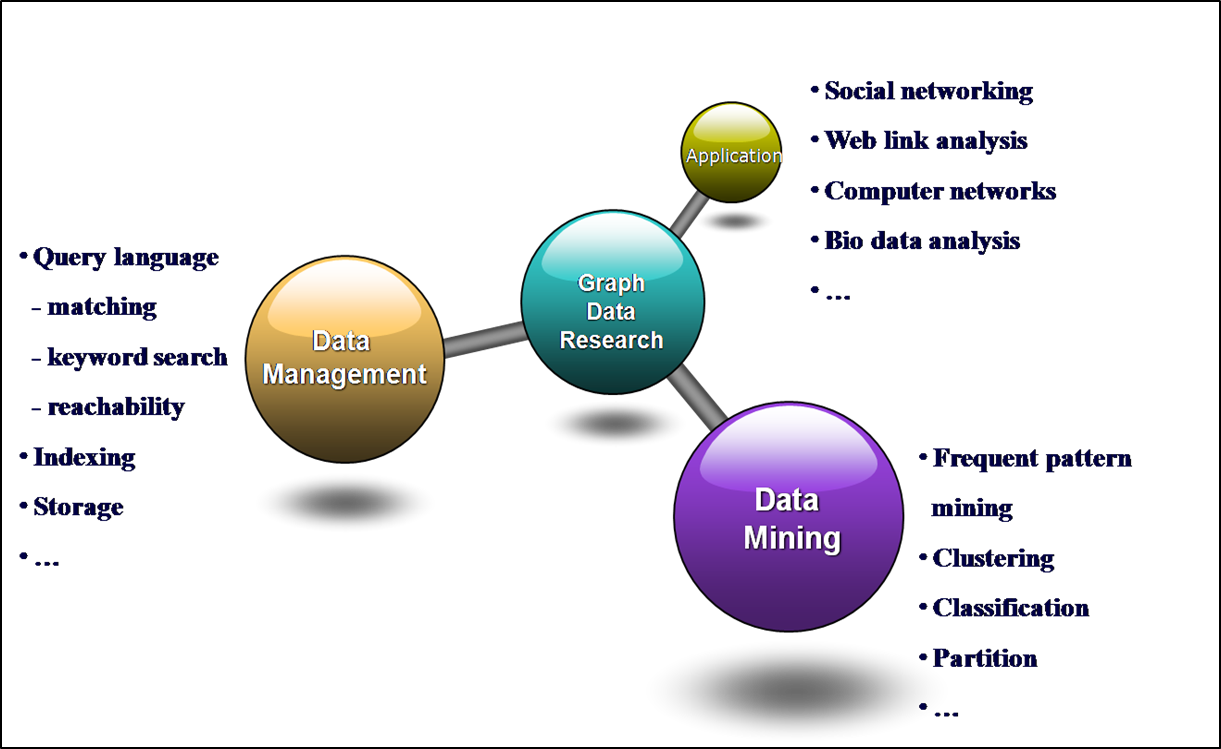
A graph, one of the most general forms of data representation, easily represents entities, their attributes, and their relationship to other entities. The problems with regard to graph data are divided into two areas: graph data management and graph data mining.
1) Graph Data Management:
Since graphs form a complex and expressive data type, we need methods for representing graphs in databases, manipulating and querying them. We study the problems of designing query languages, indexing, and retrieval structures for graph data. In addition, a number of specialized queries such as matching, keyword search and reachability queries are needed to study.
2) Graph Data Mining:
As in the case of other data types such as multidimensional or textual data, we can design mining problems for graph data. This includes techniques such as frequent pattern mining, clustering and classification. We note that these methods are much more challenging in the graph domain, because the structural nature of the data makes the intermediate representation and interpretability of the mining results much more challenging.
Query Processing in Wireless Sensor Networks
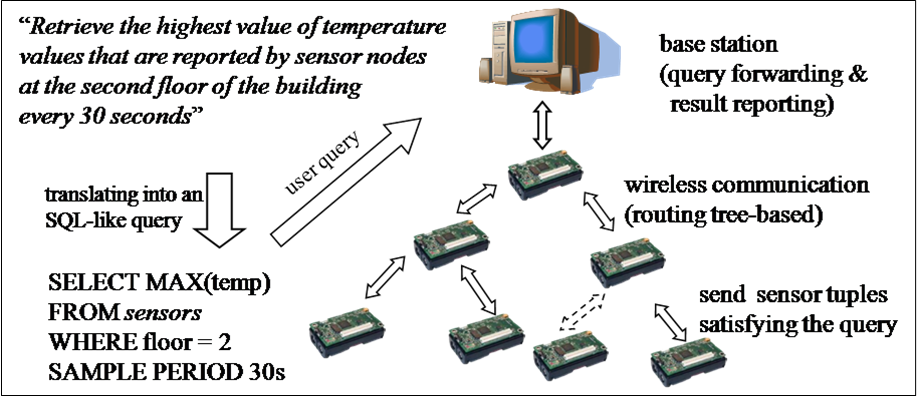
A wireless sensor network consists of spatially distributed autonomous sensor nodes to cooperatively monitor physical or environmental conditions such as temperature, sound, vibration, pressure, motion or pollutants. For the ubiquitous computing, it is now used in many industrial and civilian application areas, including industrial process monitoring and control, machine health monitoring, environment and habitat monitoring, healthcare applications, home automation, and traffic control.
A sensor database management system is a new type of DBMS that provides an SQL-like query interface for users to interact with sensor networks, which makes it easy to collect data from wireless sensor networks. It includes several strategies that minimize expensive communication by applying aggregation and filtering operations inside the sensor network and thus processes queries as energy-efficiently as possible. To process multiple queries efficiently, the sensor database management system should schedule the order of query execution and share the results among queries.
Ubiquitous Business Process Management
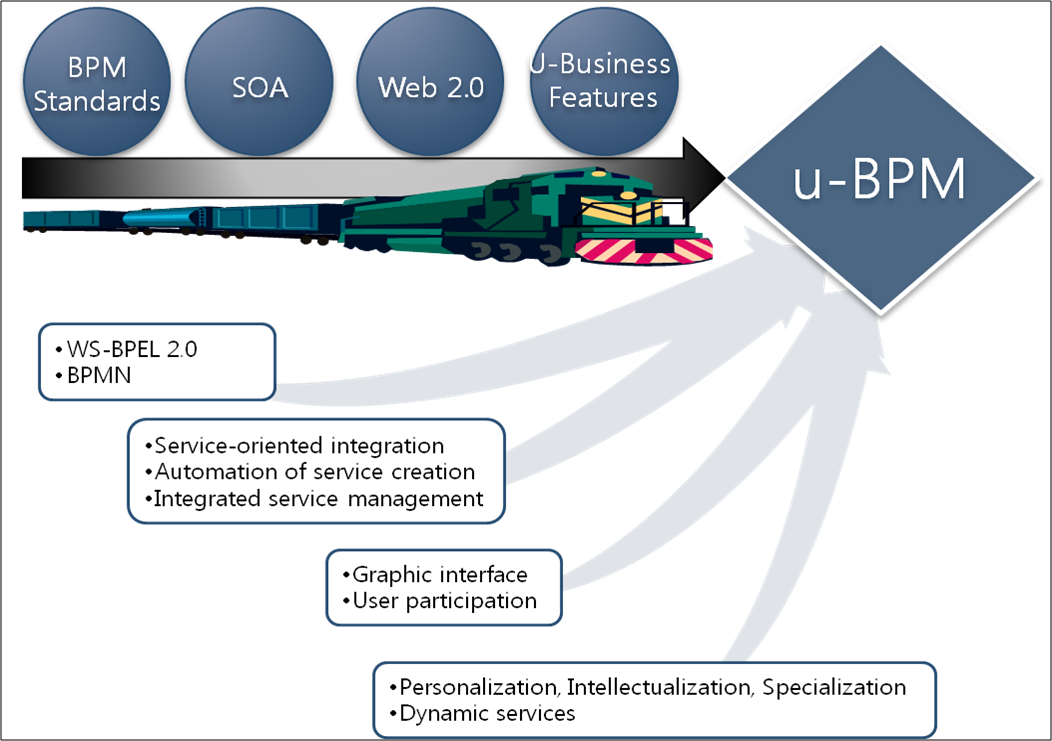
A business process (BP) is defined as a collection of related, structured activities of tasks that produce a specific service or product for a particular customer or customers. A ubiquitous business process (u-BP) is a novel type of BP that makes full use of business-related context information obtained from ubiquitous devices in order to adapt the rapid changes of business environments in a timely manner. With the traditional techniques for BP, u-BP builds on SOA to support integrated service management and uses Web 2.0 to provide user-oriented dynamic interfaces.
One of the most challenging requirements for management of u-BPs is that they need to adapt to rapidly changing business environments. In other words, u-BPs are inevitably ‘dynamic’ themselves. A ubiquitous business process management system (u-BPMS) creates, executes, and manages u-BPs by combining existing services and dealing with the ‘dynamism’ inherent in u-Business environments. u-BPMS should follow the standard models such as WfMC, BPMI and WS-BPEL, provide an integrated work environment with a convenient graphic interface, and support real-time analysis and various types of reports.
Data Stream Processing
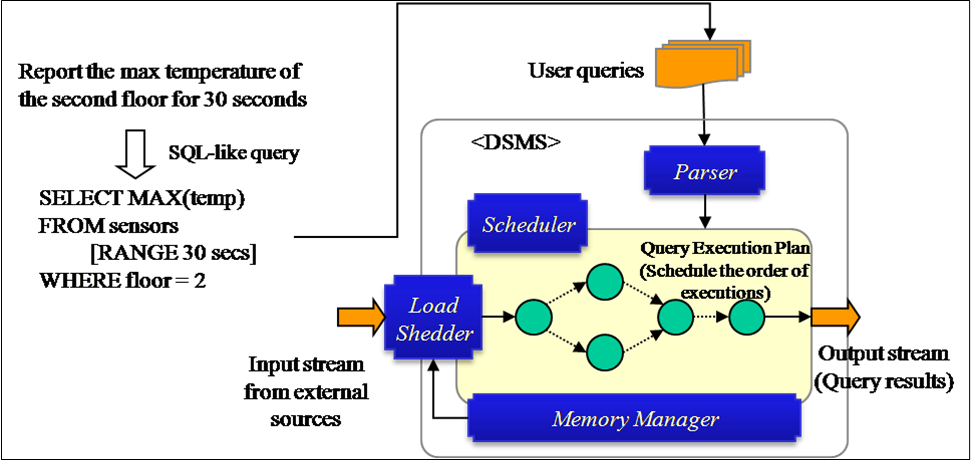
A data stream is a type of data that occurs and is collected continually like network traffic or stock prices. The Data Stream Management System (DSMS) is a collection of software modules that control the maintenance and querying of data streams. Thus, the DSMS is used in various industries like network monitoring, stock information management, etc.
The use of the DSMS to manage a data stream is roughly analogous to the use of the Database Management System (DBMS) to manage conventional databases. To get information from the data stream, the DSMS supports query languages similar to SQL. A key feature of the DSMS is the ability to execute a continuous query against a data stream. A conventional snapshot query is executed once and returns a set of results for a given point in time. In contrast, a continuous query is repeatedly executed over time. The results of the continuous query are updated as new data appears. Another feature of the DSMS is load shedding. If the DSMS becomes overloaded by fast streams, the DSMS sheds load in order to improve the latency of the response.
Semantic Web Data Processing
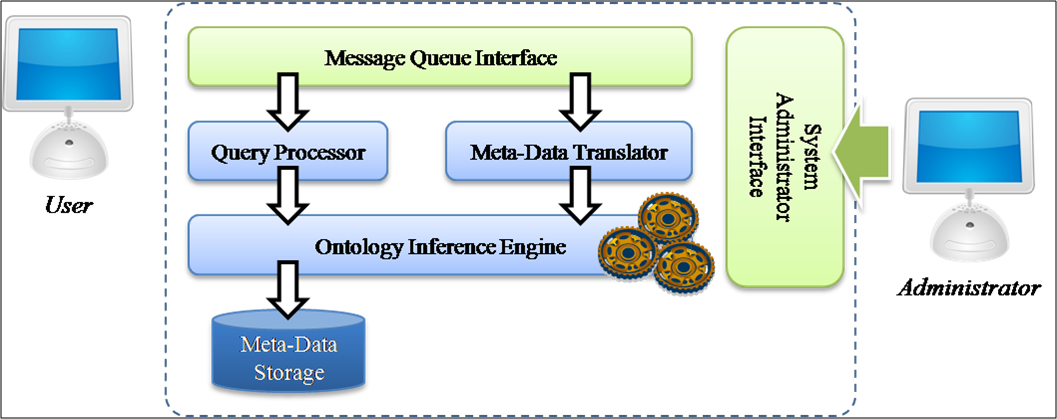
The Semantic Web is an evolving development of the World Wide Web in which the meaning (semantics) of information and services on the web is defined, making it possible for the web to "understand" and satisfy the requests of people and machines to use the web content. Users can exchange data, information, and, knowledge by using it.
The ontology can represent the knowledge in the Semantic Web by a set of concepts within a domain and the relationships between those concepts. In the database field, to process and store the ontology efficiently with database systems, design the efficient schema are key research issues. Another active research area is the semantic search. In the semantic search, the user query is not a simple sequence of words, but the concepts that are connected to each other by the certain relationships. The relationships between those concepts are examined by matching with the concepts that are described in the ontology. Using that relationship information, the semantic search engine finds the data that is close to the user’s information needs.